Version 0.7 of the psychonetrics package is now on CRAN! This version is a major restructure of the package leading to a lot of new functionality as well as much faster computations. In addition, a new pre-print is now online describing meta-analysis procedures now implemented in psychonetrics.
Free course on Structural Equation Modeling
I am teaching a course now on structural equation modeling (SEM), and am uploading every video lecture to Youtube. This playlist will be updated in the coming weeks and includes tutorial videos on psychonetrics and other R packages. For the Structural Equation Modeling course, students formed a questionnaire on measures of interest during the COVID-19 pandemic. We will release the data after the course for research and teaching purposes. If you have around 10 to 15 minutes to spare, it would be absolutely amazing if you could assist in this by filling in the questionnaire. Thanks!
Faster computations
Version 0.7 of the psychonetrics package features a major internal restructure of the computational motor. Most functions have now been translated to C++ code using the amazing RcppArmadillo package. This leads to a substantial increase in speed:
Note that because of the speed increase, verbose now defaults to FALSE, which can be altered for a model with the new setverbose function after forming the model. The default optimizer is still the R based nlminb function, but new optimizers using the package roptim have also been implemented:
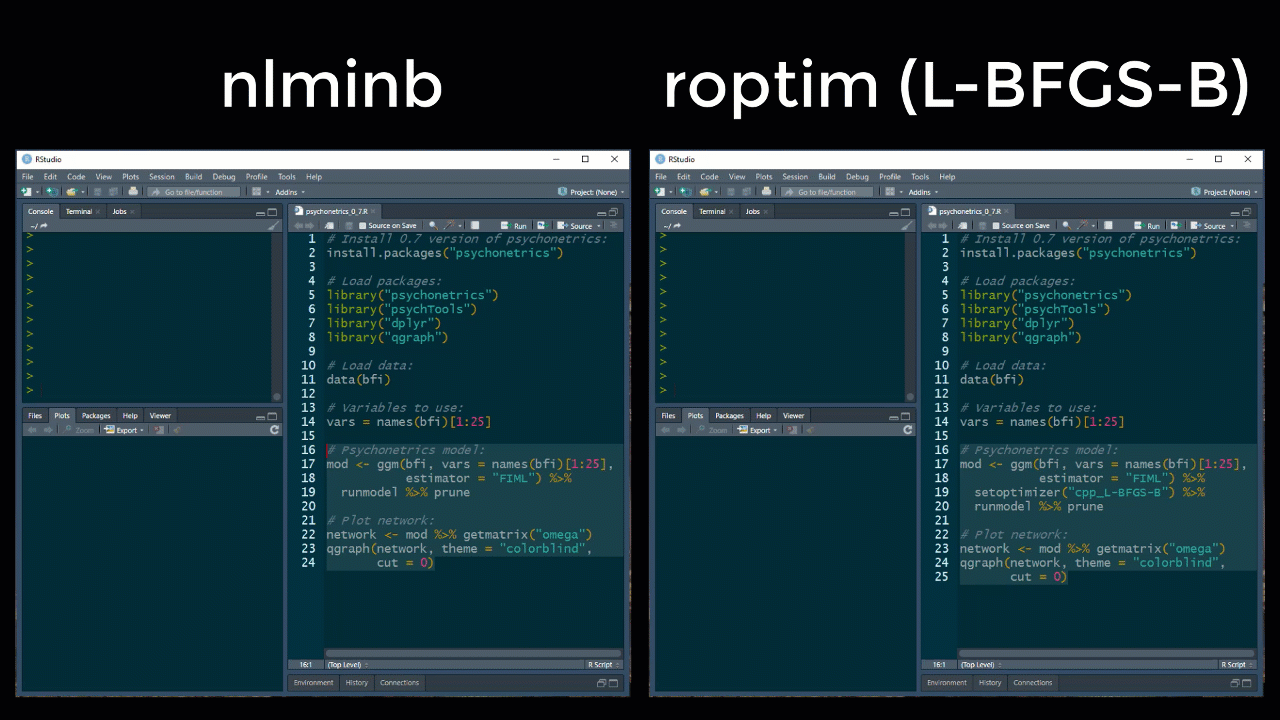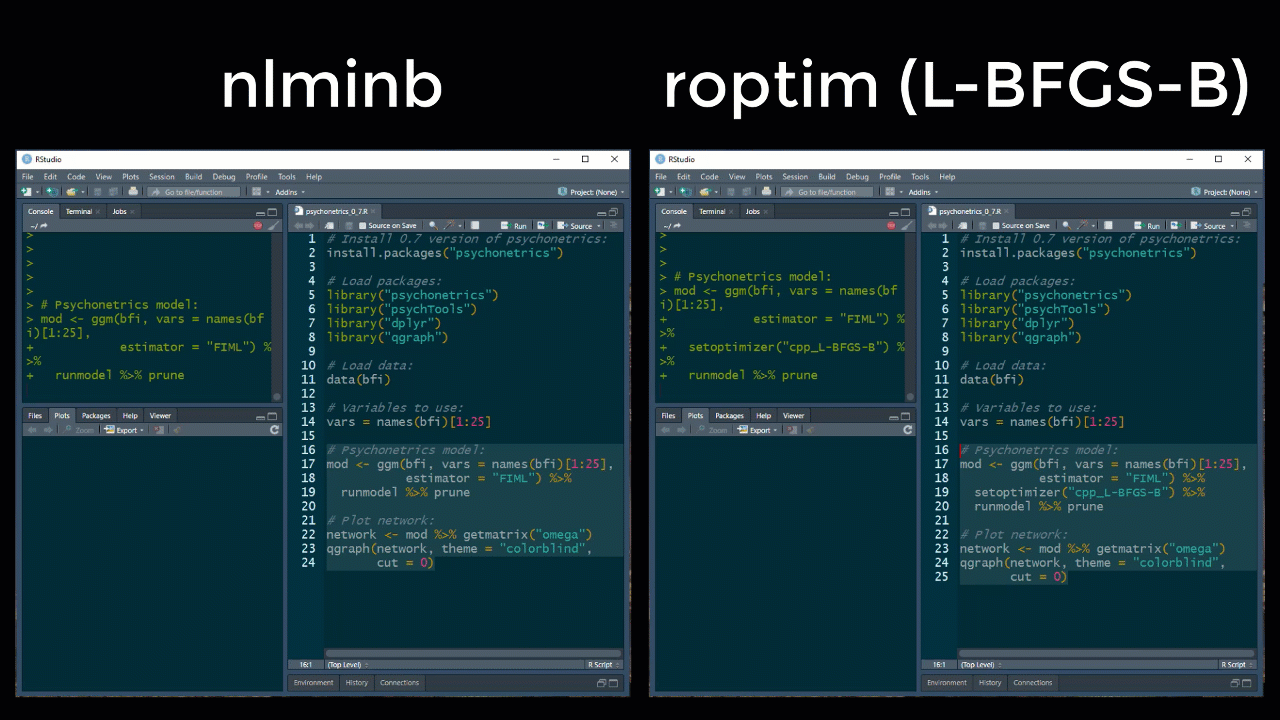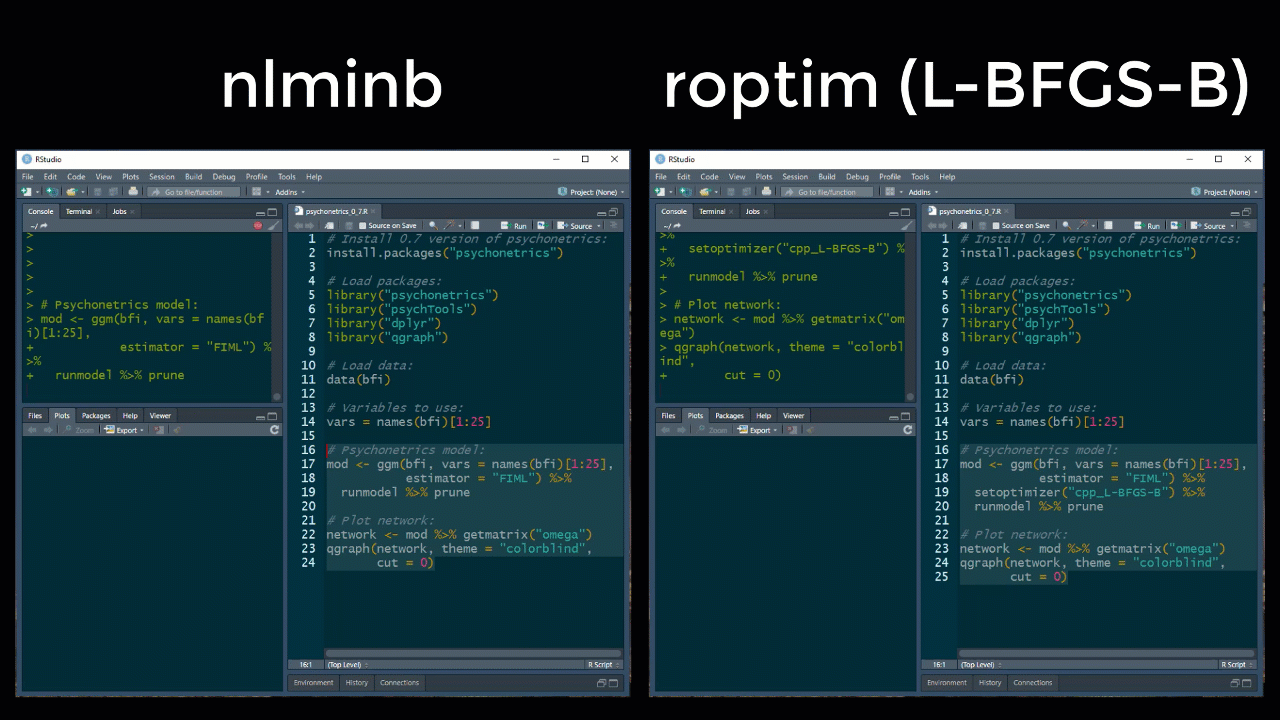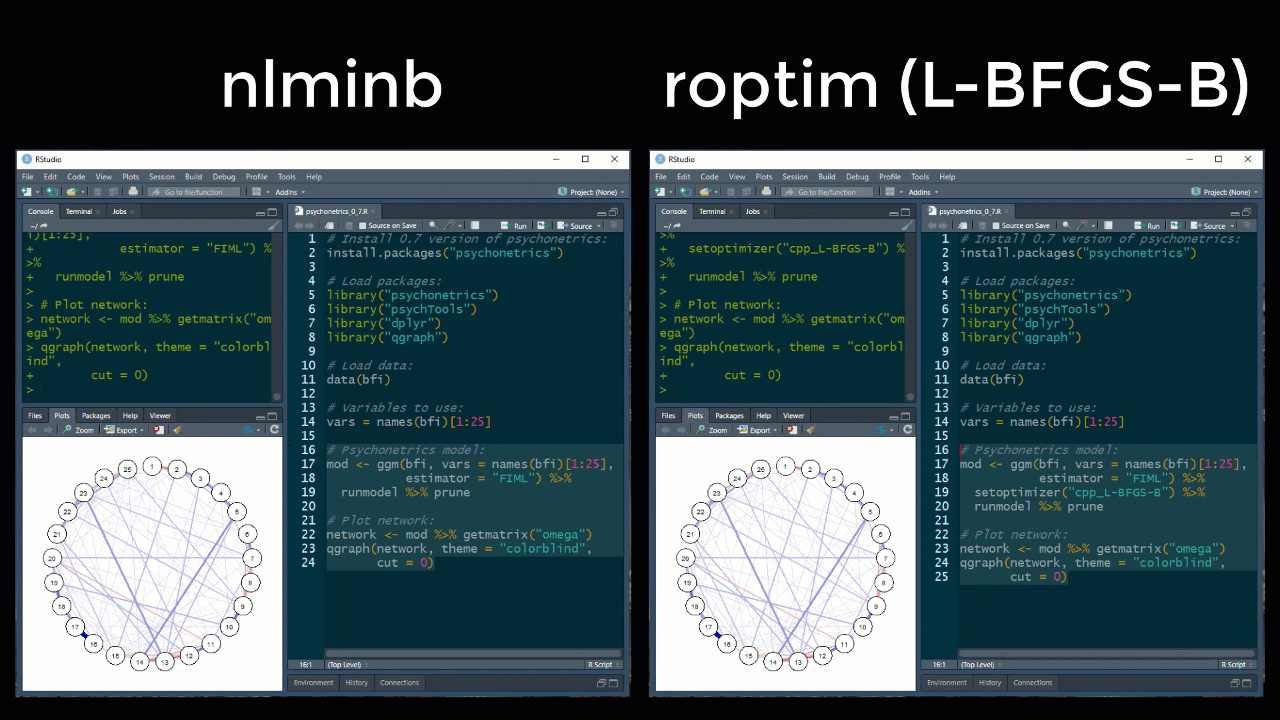
These optimizers are still somewhat unstable however, especially in the more complicated psychonetrics models. To this end, please use these with care for the moment.
Meta-analysis methods in psychonetrics
Together with Adela Isvoranu and Mike Cheung, we extended meta-analytic SEM to be used in estimating Gaussian graphical models (GGM). We call this framework meta-analytic Gaussian network aggregation (MAGNA) and describe it in our new pre-print, which has been submitted for publication in Psychometrika. The pre-print features an extensive overview of functionality in psychonetrics. First, the pre-print discusses the motor behind psychonetrics which is used in every model framework:
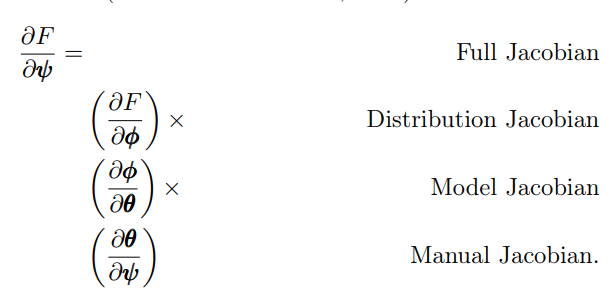
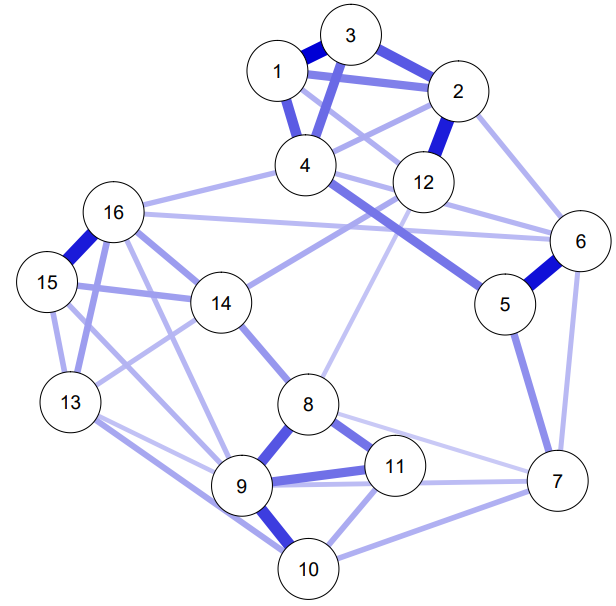
As such, the pre-print can be read as an introduction to everything psychonetrics does. Second, the pre-print includes an extensive tutorial on how to estimate GGMs from correlation matrices, including multi-group models with correlation matrices from different datasets. The latter can be used, for example, to partially pool GGM edges across groups:
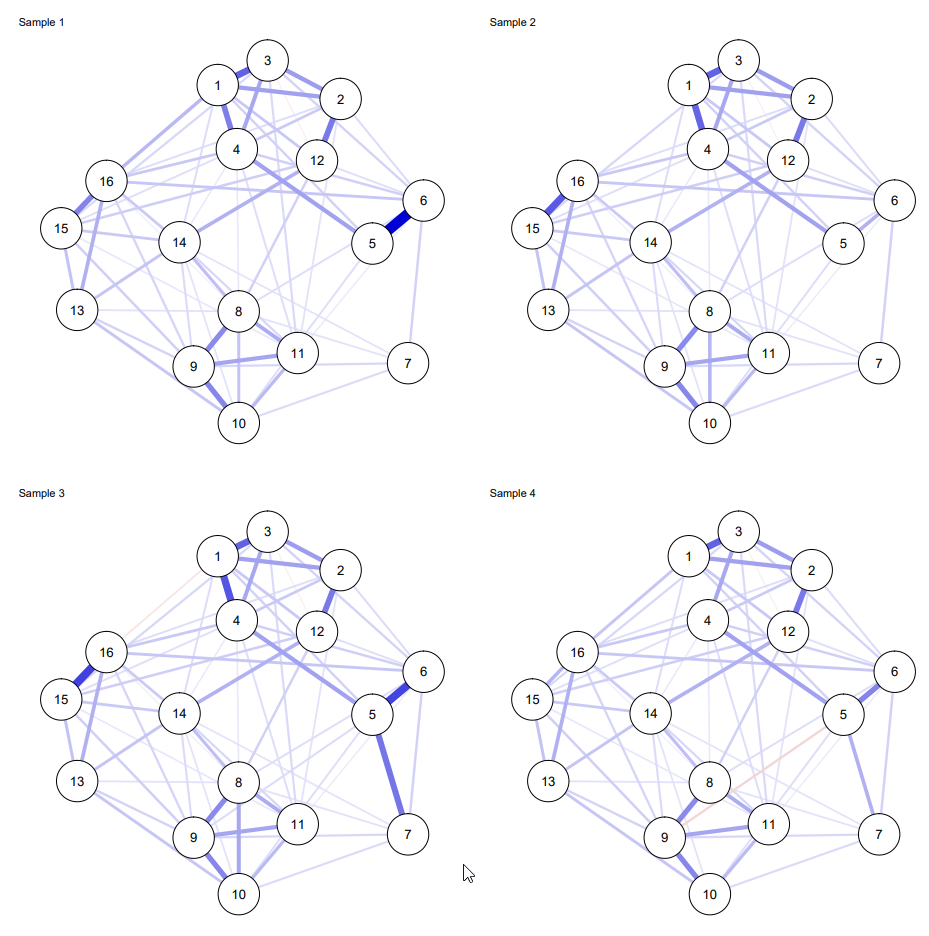
Finally, the pre-print discusses how heterogeneity across datasets (e.g., PTSD studies featuring very different traumas) can be taken into account in estimating a single GGM across potentially many datasets:
Simulation studies show that not taking such heterogeneity into account can lead to poor estimation of the common network structure:
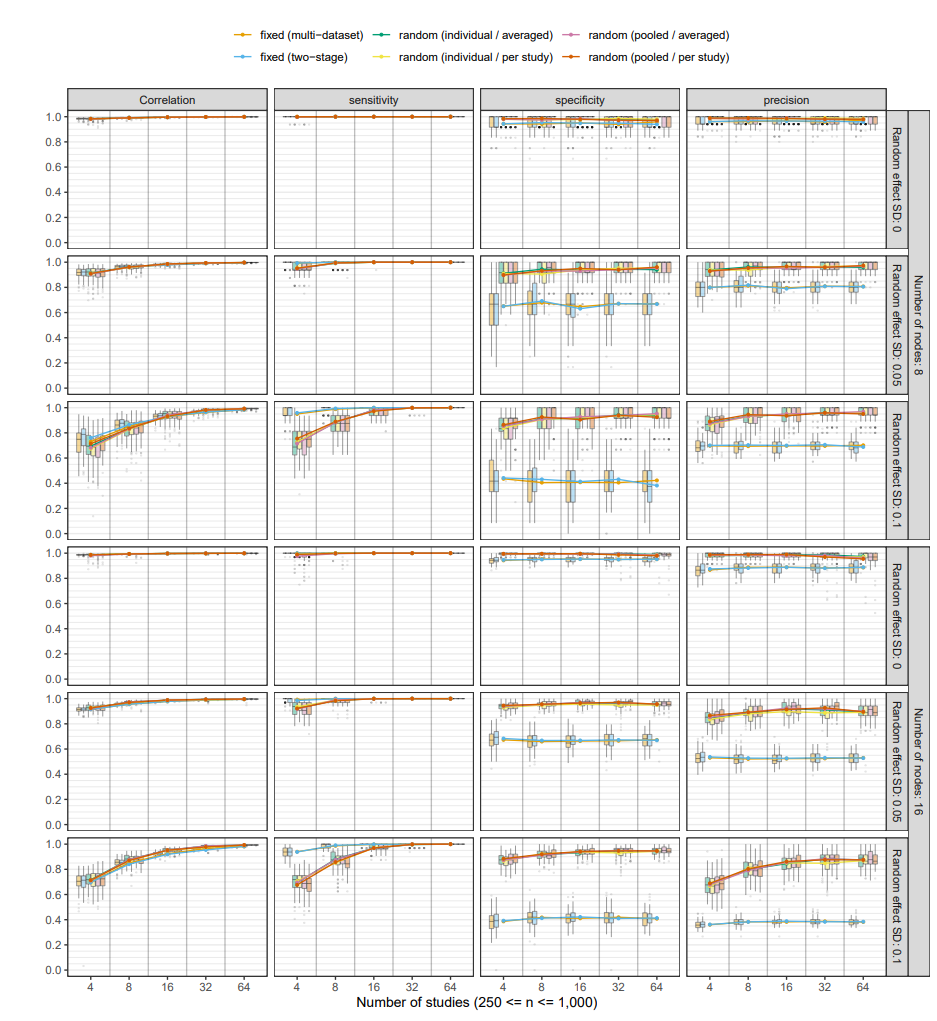
Not taking heterogeneity into account while aiming to estimate a single fixed-effects model can lead to a false positive rate more than 50%. This has some severe implications for studies aiming to aggregate or compare network models from different datasets (e.g., to study replicability) that do not take heterogeneity into account.
More new features
More functionality of psychonetrics can be found in the NEWS file on CRAN. Some earlier changes include that most latent variable models will now automatically set the factor loadings to an identity matrix if lambda is not supplied, and the new ml_tsdlvm1 allows for specifying the panel data model using the same syntax as mlVAR and graphicalVAR. Finally, the new ml_lvm function marks the first iteration of multi-level modeling. This function includes full-information maximum likelihood estimation for random-intercept lvm models (including GGMs). Of note, the computation speed is a function of the number of cases in each cluster and becomes very slow with many cases in a cluster. To this end, ml_lvm works well for dyad or small family datasets, but not well for datasets with larger clusters such as classrooms or countries.
Recent Comments